
Why Social Media Stocks Are Mispricing Youth Litigation Risk
2 hrs ago

Nvidia just guided Q2 2026 revenue to approximately $91 billion, beating analyst consensus by more than $4 billion, and simultaneously authorised an $80 billion share buyback. By conventional metrics, the AI chip market’s dominant player has never looked stronger. The complication is that the very companies writing Nvidia’s largest cheques are also building the hardware to replace it. Combined AI capital expenditure from major U.S. technology firms is projected to exceed $700 billion in 2026, nearly double the roughly $400 billion spent in 2025. That spending surge is the foundation of Nvidia’s current dominance. It is also the engine funding in-house silicon programmes at Alphabet, Amazon, and Microsoft that represent the most credible long-term competitive threat to the company’s chip franchise. What follows maps the structural competitive pressures on Nvidia’s position, explains why the inference market is the real strategic battlefield, and assesses what the company’s partnership with Groq signals about how it intends to defend its lead.
AI capex in context: Combined U.S. tech firm AI capital expenditure reached approximately $400 billion in 2025 and is projected to exceed $700 billion in 2026, a near-doubling in a single year.
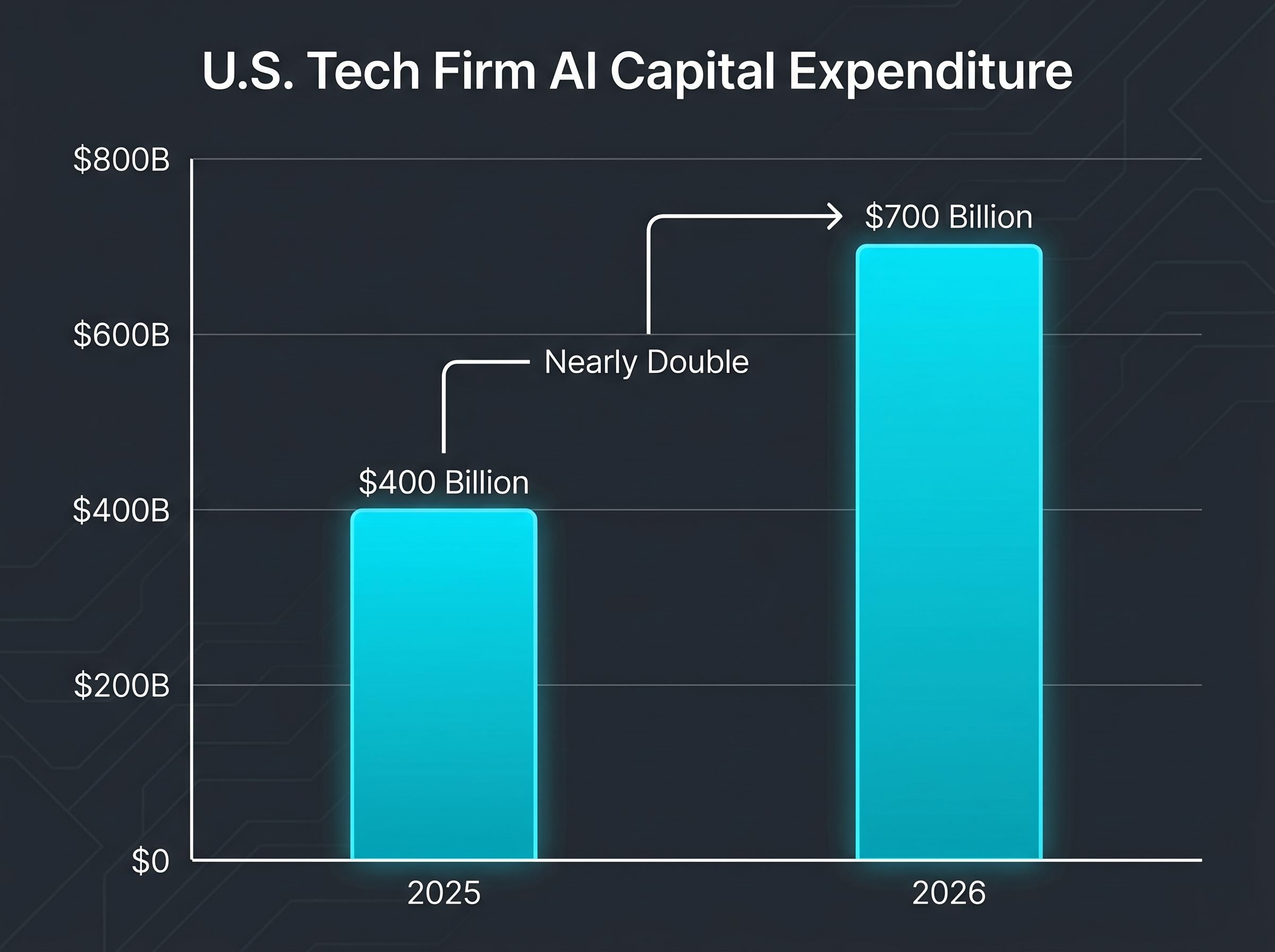
That figure is the single most important number in the semiconductor industry right now. It validates Nvidia’s near-term financial trajectory; Nvidia’s processors power nearly all major global data centres and underpin the most sophisticated AI systems currently in production, and the company’s Q2 2026 revenue guidance of approximately $91 billion (versus LSEG consensus of $86.84 billion) reflects how much of that spending still flows directly through its order book.
The hyperscaler capex trajectory has accelerated beyond earlier projections, with Amazon, Microsoft, Alphabet, and Meta collectively spending $130 billion in Q1 2026 alone and full-year 2026 combined guidance now reaching approximately $725 billion, a figure that has since been revised upward from the $700 billion estimate used in earlier analyst models.
The paradox is structural. A growing portion of that same capital is being redirected into custom silicon research and development, internal chip manufacturing, and dedicated inference hardware. The three largest hyperscalers are simultaneously Nvidia’s biggest customers and its most organised competitors:
The capex numbers that look like pure tailwinds today contain the funding mechanism for future demand diversion.
AI chip workloads split into two fundamentally different categories, and understanding the distinction is a prerequisite for reading the competitive map accurately.
Training is the process of building an AI model from scratch: feeding massive datasets through neural networks over weeks or months to establish the patterns the model will use. These workloads are computationally intensive, relatively infrequent, and concentrated in a small number of very large clusters. Inference is what happens after a model is trained: every time a user asks a chatbot a question, every time an image is generated, every time a recommendation engine ranks results, the model runs an inference operation. Inference workloads are distributed, continuous, and extremely cost-sensitive at scale.
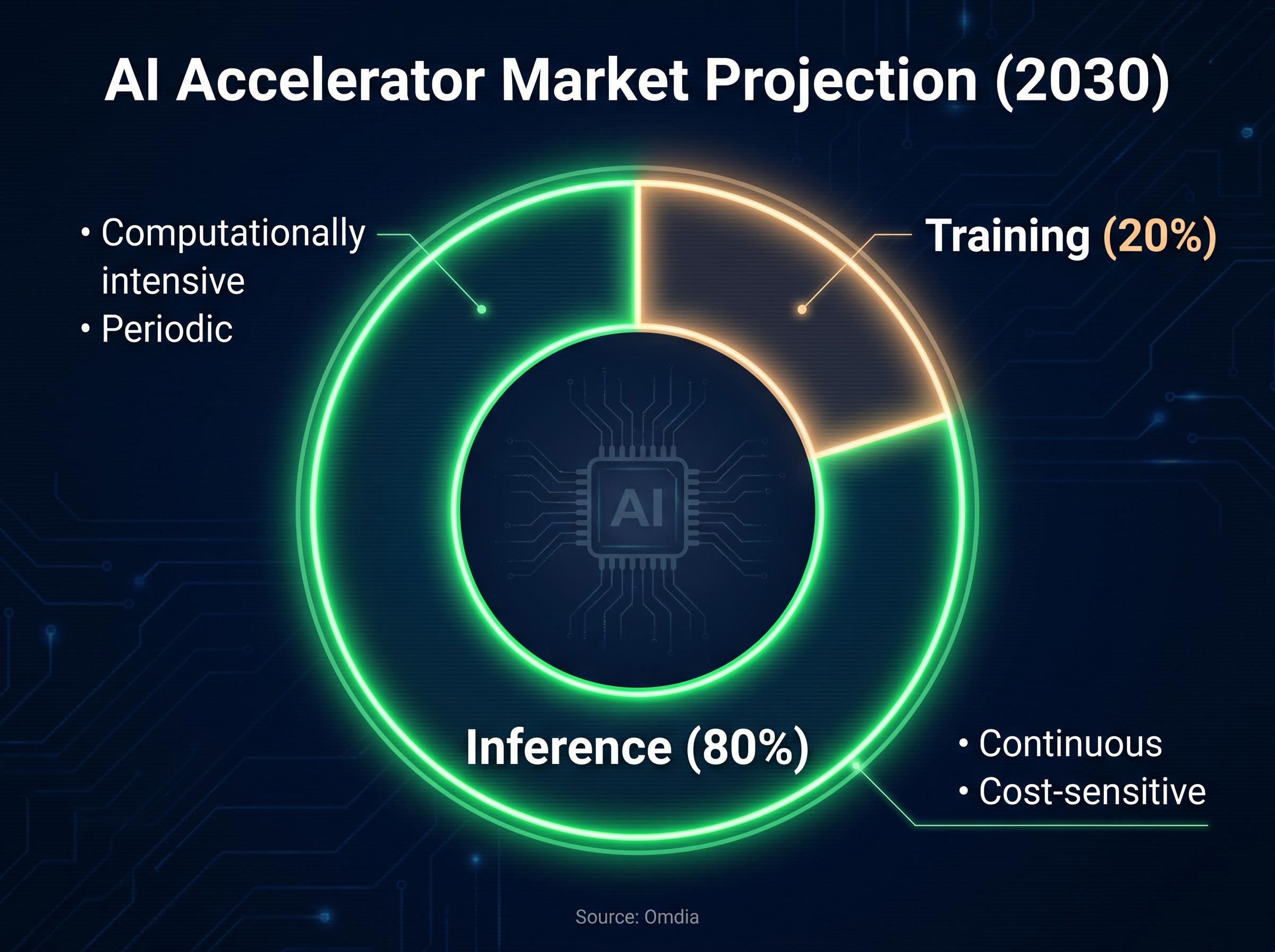
The market size implications are significant. According to Omdia, inference is projected to account for approximately 80% of the AI accelerator market by 2030, with training at approximately 20%. Analyst consensus from BofA, Morgan Stanley, and Bernstein consistently identifies inference as the faster-growing segment. Both AMD and Intel have publicly highlighted inference revenue potential as a core commercial target.
| Attribute | Training | Inference |
|---|---|---|
| Workload type | Model building, computationally intensive | Model deployment, distributed operations |
| Frequency | Periodic (weeks/months per training run) | Continuous (millions of queries per day) |
| Cost sensitivity | Lower (concentrated, high-value runs) | Higher (volume-driven, cost-per-query matters) |
| Custom chip viability | Low (requires flexibility and broad programmability) | High (repetitive, well-defined operations) |
Inference runs repetitive, well-defined operations on fixed model weights, making it amenable to purpose-built silicon optimised for a narrow task. Training, by contrast, requires flexibility, large memory bandwidth, and general-purpose programmability that is harder to replicate without Nvidia’s ecosystem depth. That asymmetry is the reason hyperscaler custom chips concentrate on inference first: it is where purpose-built silicon can most credibly compete on cost-per-operation.
Agentic AI inference workloads favour CPU architecture for sequential reasoning and agent orchestration tasks, with industry estimates placing 35-45% of inference operations as CPU-bound rather than GPU-bound, a segmentation that partially explains why hyperscaler custom silicon investments have concentrated on inference first and why the custom chip threat to Nvidia is more workload-specific than headline market-share figures suggest.
The strategic intent is consistent across all three hyperscalers. The quantitative evidence remains thin.
Google’s TPU v5p pods are described by Google Cloud as “most powerful, scalable, and flexible,” with the TPU v5e targeting cost-efficient inference. The 50-70% price-performance improvement is cited versus prior TPU generations, not versus Nvidia GPUs directly. Alphabet CFO Ruth Porat reiterated in the Q4 2024 earnings call (30 January 2025) that the company continues investing in TPUs to “optimise performance and costs” for AI, without providing numerical disclosures on deployment scale or GPU displacement.
AWS positions Trainium2 and Inferentia2 against Nvidia, with a stated up to 2x better price-performance versus comparable GPU instances, though that comparison originates from late 2023/2024 data and has not been publicly updated. Microsoft’s Maia AI Accelerator, announced November 2023, was described in 2025 reporting as being “rolled out” alongside continued large-scale Nvidia GPU purchases.
| Company | Product | Primary workload target | Stated price-performance claim | Deployment status |
|---|---|---|---|---|
| TPU v5p / v5e | Training and inference | 50-70% vs prior TPU generation | Generally available on Google Cloud | |
| Amazon | Trainium2 / Inferentia2 | Training and inference | Up to 2x vs comparable Nvidia GPU instances | Available on AWS |
| Microsoft | Azure Maia | Training and inference | No public benchmark vs Nvidia | Rolling out alongside Nvidia GPUs |
What all three share is a critical disclosure gap: no hyperscaler has publicly quantified what share of AI workloads runs on custom silicon or provided numeric guidance indicating a material reduction in Nvidia GPU purchases. The strategic direction is clear. The financial impact remains unquantified.
Both AMD and Intel position themselves as credible Nvidia alternatives in an inference-led market. Both face the same analytical limitation: inference-specific revenue is not reported separately in either company’s public disclosures.
AMD:
Intel:
For investors evaluating whether AMD or Intel represent meaningful alternatives in an inference-led market, the absence of inference-specific disclosures is a material analytical gap. Market share claims for inference cannot be independently verified from public filings, and position sizing should reflect that uncertainty.
Chip specifications are only half the competitive equation. Nvidia’s CUDA software ecosystem, including cuDNN, TensorRT, and integrated DGX/HGX systems, is consistently characterised by analysts at BofA, Morgan Stanley, and Bernstein as the primary reason hyperscaler custom chips and AMD/Intel alternatives have not translated into rapid market share erosion. Developers default to CUDA, and the toolchain gap for alternatives remains real. Hyperscaler ASICs are tightly integrated into their own cloud environments but lack a comparable horizontal software ecosystem.
Nvidia’s platform valuation has become the central analytical debate among Wall Street analysts, with Goldman Sachs, Morgan Stanley, and William Blair now decomposing data centre revenue into four distinct layers: GPU silicon, networking, systems, and software, each carrying different margin and growth characteristics that complicate simple price-to-earnings comparisons with pure-play chip companies.
That software moat explains the current defensibility. The Groq deal reveals where Nvidia sees the next vulnerability.
Groq licensing deal: $20 billion non-exclusive licensing agreement announced 24 December 2025, covering Groq’s LPU inference technology and including an acquihire of founder Jonathan Ross and President Sunny Madra.
The deal’s timeline and product integration followed a clear sequence:
By licensing purpose-built inference architecture and absorbing the engineering talent behind it, Nvidia is reinforcing its position in the exact market segment where competitors have the most credible claim to a cost-performance advantage. The deal is not a product announcement in isolation; it is evidence that Nvidia’s leadership recognises where its franchise is most exposed and is willing to pay at scale to close that gap. That strategic awareness is itself a data point for investors assessing long-term durability.
Nvidia’s near-term financial position is extraordinary. The $91 billion Q2 guidance, the $80 billion buyback authorisation, and a dividend raised from $0.01 to $0.25 per share all reflect a company operating at peak financial strength.
The medium-to-long-term picture is more contested. Inference market commoditisation, hyperscaler silicon maturity, and developer ecosystem competition represent structural risks on a 3-5 year horizon. None of these threats is yet quantifiable from public disclosures. That is precisely what makes the current moment uncomfortable for long-term positioning: the threat is credible but unmeasurable.
The capex-to-revenue lag estimated at 18-24 months by Morningstar analysts is the structural timing risk that separates Nvidia’s near-term order book strength from the medium-term question of whether hyperscaler spending sustains at current levels once the revenue justification for that spending comes under scrutiny in 2027 earnings cycles.
Nvidia’s window of dominance is open. The competitive forces described in this analysis are better-funded and more structurally organised than at any prior point. Investors tracking this dynamic should monitor hyperscaler earnings calls for workload-mix disclosures, AMD and Intel segment reporting for inference revenue disaggregation, and Nvidia’s Vera Rubin platform rollout milestones as the clearest near-term signals of whether the company’s defensive strategy is keeping pace with the threats it was designed to address.
This article is for informational purposes only and should not be considered financial advice. Investors should conduct their own research and consult with financial professionals before making investment decisions. Forward-looking statements regarding market size, competitive positioning, and company strategies are subject to change based on market developments and company performance.
Training chips build AI models from scratch using massive datasets over weeks or months, requiring flexibility and broad programmability. Inference chips handle every query a deployed model answers, running repetitive, well-defined operations where purpose-built silicon can compete most effectively on cost-per-operation.
According to Omdia, inference is projected to account for approximately 80% of the AI accelerator market by 2030, with training representing the remaining 20%, making inference the primary commercial battleground for chip competition.
Nvidia announced a $20 billion non-exclusive licensing agreement with Groq in December 2025, covering Groq's LPU inference technology and including an acquihire of key founders. The deal signals that Nvidia recognises inference cost-per-token performance as its most exposed competitive flank and is investing heavily to defend it.
All three hyperscalers have developed custom AI silicon, including Google's TPU v5, Amazon's Trainium2 and Inferentia2, and Microsoft's Azure Maia, but none has publicly quantified what share of workloads runs on custom silicon or disclosed a material reduction in Nvidia GPU purchases.
Investors should monitor hyperscaler earnings calls for any workload-mix disclosures showing migration from Nvidia GPUs to custom silicon, AMD and Intel segment reporting for inference revenue disaggregation, and commercial uptake of Nvidia's Groq 3 LPU within its Vera Rubin platform.




