Broadcom reported $4.1 billion in AI semiconductor revenue in Q1 2025, up 77% year over year, from a company most people outside the chip industry have never heard of. That number tells a story the Nvidia headlines do not. The dominant narrative of the AI infrastructure boom centres on Nvidia and its GPU dominance, but a quieter, structurally significant shift is underway: the largest cloud operators in the world are commissioning their own chips, built from scratch for specific AI tasks. Broadcom’s revenue figures are the clearest financial signal that this parallel market is not theoretical; it is already generating billions.
What follows explains what custom AI chips actually are, why hyperscalers are building them, who is winning the contracts, and what the broader semiconductor market rally signals about the durability of the AI infrastructure investment cycle. The goal is a framework for understanding the AI chip market beyond the Nvidia narrative.
Why the AI chip conversation changed in 2025
Broadcom’s $4.1 billion quarter was not a fluke. The company guided to over $4.4 billion in Q2 2025, representing 46% year-over-year growth. Those figures reflect something more than one company’s momentum; they reflect a structural change in how AI infrastructure is being built.
Hyperscaler capital expenditure rose approximately 54% in 2024, adding almost $80 billion annually to AI infrastructure spending. That scale of investment created a problem that a single chip architecture could not optimally solve. As AI workloads diversified, from recommendation engines to content ranking to agentic systems, the economics of running every task on the same general-purpose GPU began to break down.
AI infrastructure spending relative to historical tech cycles provides one of the more grounding perspectives on the current buildout: US IT spending reached 4.9% of GDP in Q1 2026, surpassing the dot-com peak of approximately 4.2%, a comparison that reframes the scale of what hyperscaler capex is actually doing to the broader economy.
“The monolithic GPU as the default AI compute platform is ending.” — HTEC, 2026 semiconductor trends report
The distinction that matters for understanding this shift is between two categories of AI compute:
- Frontier model training: novel, evolving workloads where GPU flexibility is irreplaceable because researchers need to iterate on model architectures rapidly.
- Production inference at volume: stable, repetitive workloads where custom silicon can win on cost per unit and energy efficiency because the task is well-defined and runs billions of times per day.
The first category still belongs to Nvidia. The second is where custom chips are gaining ground, and it is growing faster.
When big ASX news breaks, our subscribers know first
What ASICs are and how they differ from GPUs
An application-specific integrated circuit (ASIC) is a chip designed to perform a narrow range of tasks with maximum efficiency, rather than a broad range of tasks with flexibility. Where a GPU is built to handle many different computational problems, an ASIC is engineered for one type of workload, or a small family of related workloads, and stripped of the overhead that general-purpose flexibility requires.
That overhead is not trivial. A GPU’s programmability is what makes it powerful for novel research, but it comes at a cost: additional silicon, higher energy consumption per operation, and more expense per inference unit. When a workload is still being developed, that flexibility is worth the premium. When a workload has stabilised and runs at massive scale, it becomes an expense that custom silicon can eliminate.
The flexibility-efficiency trade-off at scale
The economics of building a custom ASIC only make sense when workloads are stable enough and large enough to amortise the design cost across millions (or billions) of inferences. ASIC design carries higher upfront cost and the risk that the chip’s fixed-function architecture could be outpaced by rapid shifts in AI model design, as PwC cautions regarding architectural lock-in.
This is precisely the condition hyperscalers meet. Google, Meta, Amazon, and Microsoft run the same recommendation, ranking, and content understanding models billions of times per day. At that volume, as Deloitte’s 2026 industry outlook frames it, ASICs function as cost-optimised production engines while GPUs serve as general-purpose research workhorses.
| Attribute | GPU | ASIC | Notes |
|---|---|---|---|
| Flexibility | High | Low | GPUs handle diverse, evolving workloads; ASICs are optimised for specific tasks |
| Upfront cost | Lower (off-the-shelf) | Higher (custom design) | ASIC design cycles span years before deployment |
| Energy efficiency at scale | Moderate | High | ASICs eliminate overhead from unused general-purpose circuitry |
| Ideal workload type | Novel, rapidly evolving models | Stable, high-volume inference | Complementary rather than competing |
How the biggest cloud operators are building their own silicon
Four of the world’s largest cloud operators are developing custom AI chips. These are not isolated experiments; they represent a pattern driven by the same economic logic across each company.
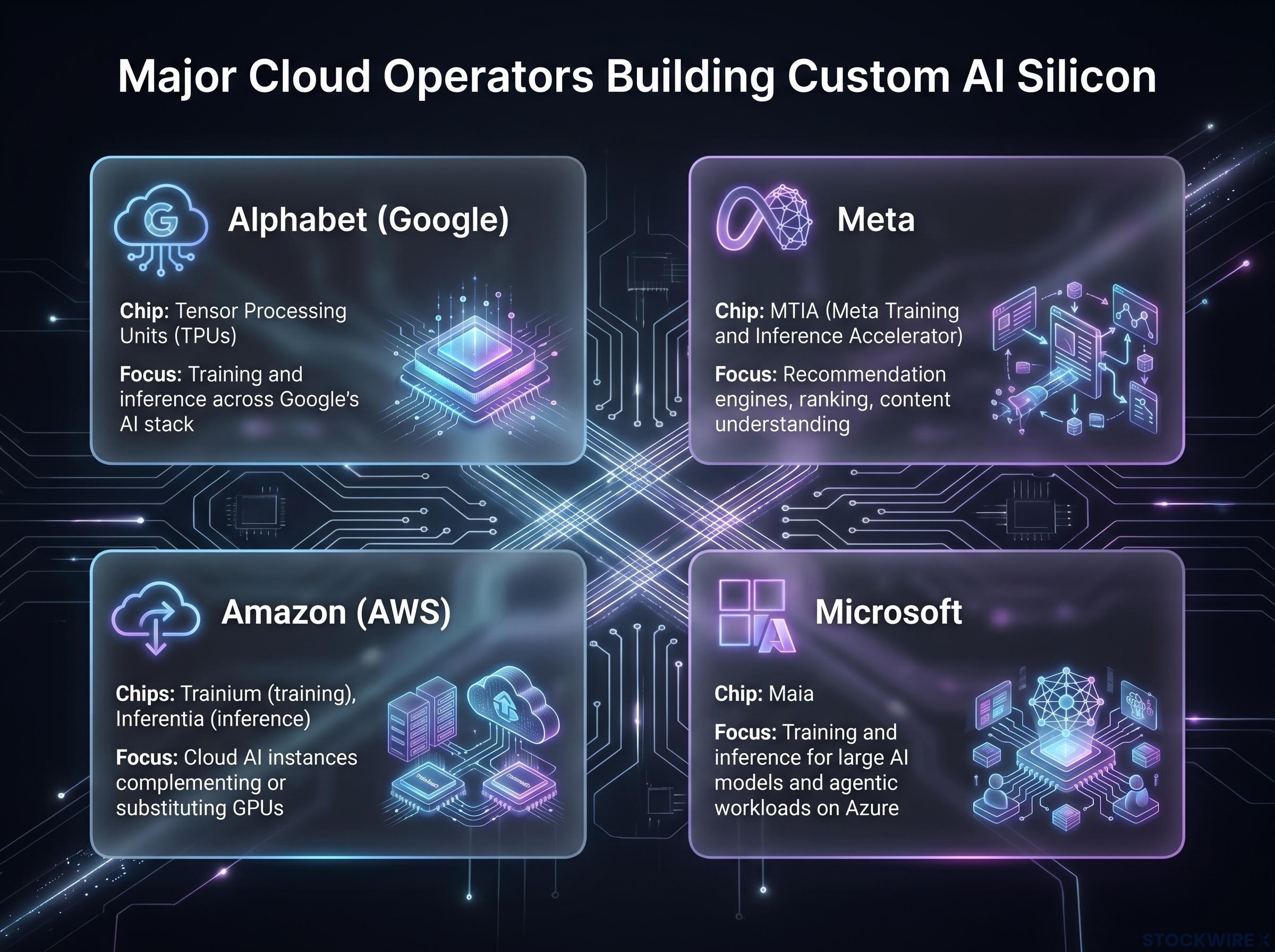
| Company | Custom chip programme | Primary workload focus |
|---|---|---|
| Alphabet (Google) | Tensor Processing Units (TPUs) | Training and inference across Google’s AI stack |
| Meta | MTIA (Meta Training and Inference Accelerator) | Recommendation engines, ranking, content understanding |
| Amazon (AWS) | Trainium (training), Inferentia (inference) | Cloud AI instances complementing or substituting GPUs |
| Microsoft | Maia | Training and inference for large AI models and agentic workloads on Azure |
The strategic rationale is consistent across all four programmes:
- Cost containment: custom silicon reduces the per-inference cost once workloads are stable and volume is high enough to amortise design expenses.
- Energy efficiency: ASICs built for specific tasks consume less power per operation than general-purpose GPUs running the same workload.
- Supply chain control: designing proprietary chips reduces dependence on a single external supplier for the most performance-sensitive components in the data centre.
- Software stack integration: custom hardware can be tightly coupled to each company’s proprietary models and frameworks, improving end-to-end performance.
None of these programmes eliminate GPU use. According to industry analysis from StartUs Insights, hyperscalers are deploying bespoke ASICs alongside Nvidia platforms, particularly for steady, high-volume inference. Each company continues to rely on Nvidia GPUs for frontier model development, where the flexibility of general-purpose compute remains necessary.
The combined market capitalisation of these four companies exceeds a trillion dollars. Their simultaneous pursuit of the same architectural strategy is the clearest available evidence that custom silicon is a structural feature of AI infrastructure, not a speculative experiment.
The strategic paradox underlying hyperscaler custom silicon programmes is that the same capital expenditure wave funding Nvidia’s record order book is simultaneously bankrolling the ASIC design efforts at Alphabet, Amazon, and Microsoft that represent the most credible long-term alternative to GPU-based inference.
Why Broadcom is winning the custom chip contracts
The buyer side of the custom silicon story explains why hyperscalers want ASICs. The supplier side explains why Broadcom’s revenue is growing at this pace.
Broadcom Q1 2025 AI revenue: $4.1 billion, up 77% year over year.
Broadcom operates a fundamentally different model from Nvidia. Where Nvidia designs and sells standardised GPUs, Broadcom functions as a contract ASIC design and supply partner for hyperscalers. It designs chips to a customer’s specifications, then manufactures and delivers them at scale. Broadcom CEO Hock Tan has cited custom AI accelerators and AI networking solutions as the primary drivers of the company’s AI revenue growth.
That revenue breaks into two streams:
- Custom AI accelerator ASICs: chips designed to hyperscaler specifications for specific inference and training workloads, representing the core of the custom silicon thesis.
- High-speed networking silicon: Ethernet and switching silicon used in AI data centres to connect accelerators at the speeds required for distributed AI workloads.
Industry coverage from 2025-2026 primarily cites Broadcom as the flagship example of hyperscaler ASIC success. Marvell Technology is also active in the hyperscaler ASIC and AI networking markets and is acknowledged in semiconductor trend analyses as a beneficiary of the AI infrastructure build-out, though its AI-specific revenue figures are less publicly detailed than Broadcom’s during this period.
The distinction matters for investors: Broadcom’s disclosed figures provide a concrete financial yardstick for the custom silicon market’s scale, making it possible to track whether this revenue stream reflects durable structural demand or cyclical spending.
What the semiconductor market rally is signalling
The corporate strategy narrative has a market-level counterpart. The Philadelphia Semiconductor Index (SOX) had risen approximately 96.5% year-to-date as of 3 June 2026, with the index at approximately 13,917. Earlier in 2026, the SOX recorded its longest consecutive daily winning streak on record.
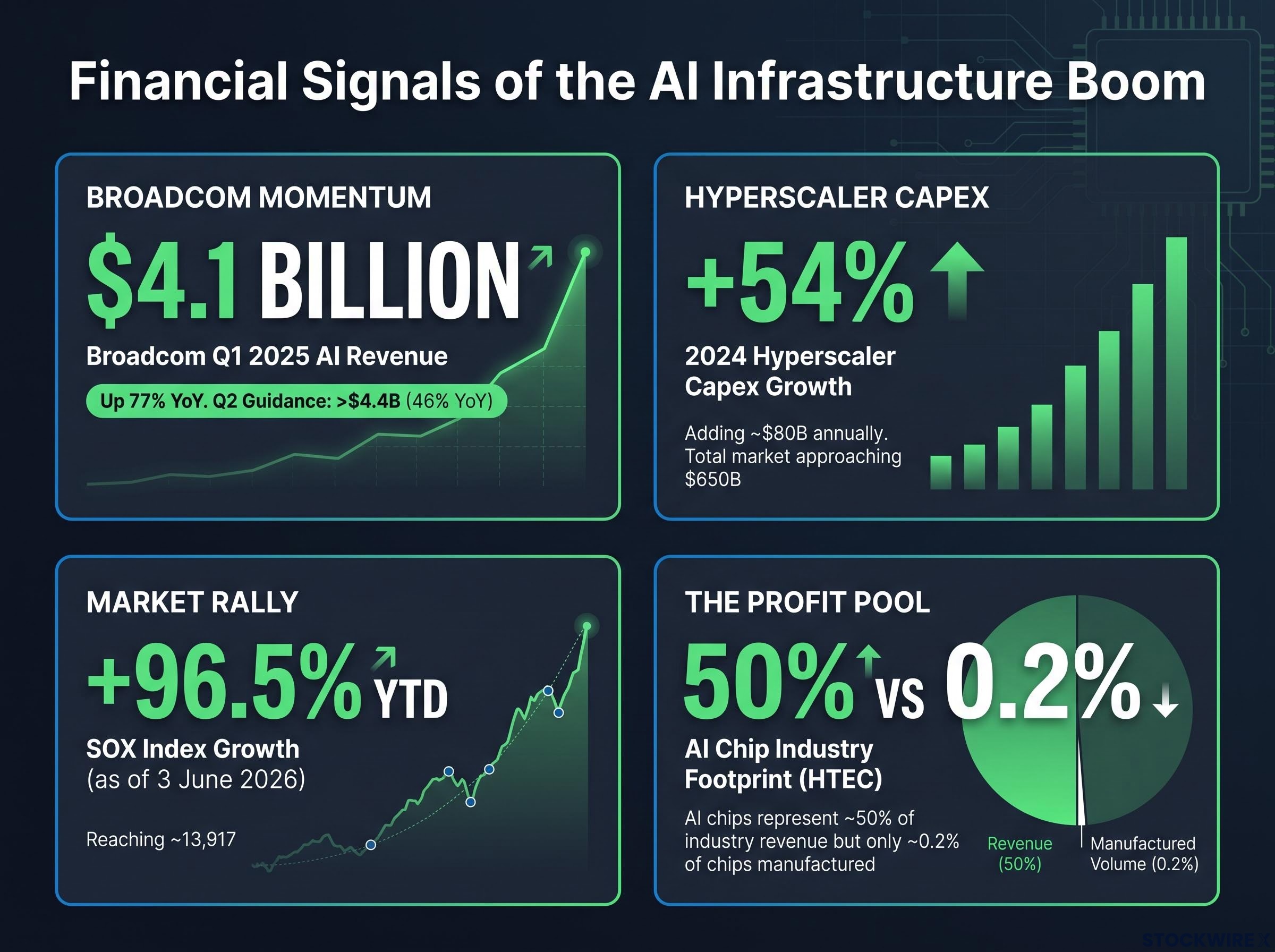
SOX performance: approximately 96.5% year-to-date as of 3 June 2026, with the index’s longest consecutive daily winning streak on record set earlier this year.
Those figures reflect investor conviction that the AI infrastructure spending cycle has durability, not just momentum. Three signals anchor that conviction:
- SOX performance: the index’s near-doubling in the first half of 2026 reflects capital flowing into the semiconductor sector at a pace that implies multi-year demand expectations, not a short-cycle trade.
- Hyperscaler capex growth: capital expenditure across the four major cloud operators rose approximately 54% in 2024. AI infrastructure spending is estimated to be approaching $650 billion in total, according to industry estimates.
- AI chip revenue concentration: AI chips reportedly represent approximately 0.2% of all chips manufactured but approximately 50% of industry revenue, according to HTEC’s analysis, underscoring that the profit pool is concentrated in exactly the category where custom silicon competes.
The co-existence model is relevant here. The custom silicon thesis does not require Nvidia to lose. It requires AI infrastructure investment to remain at elevated levels long enough to justify multi-year ASIC design cycles. The SOX rally, driven by both GPU and ASIC beneficiaries, suggests investors are pricing in exactly that durability.
Semiconductor supercycle durability is the central question the SOX rally forces investors to answer: the $3.8 trillion added to sector market capitalisation over six weeks in 2026, combined with agentic AI workloads converting episodic chip demand into permanent baseline consumption, provides the most detailed available evidence that the current cycle has structural underpinnings the dot-com era lacked.
The limits of custom silicon and what could go wrong
The structural case for custom AI chips carries a specific vulnerability, and it is not demand. It is the speed at which AI model architectures evolve.
An ASIC optimised for today’s model architecture may underperform or become obsolete if model designs shift substantially during the chip’s useful life. Custom ASICs take years to design, tape out, and deploy at scale. AI model architectures, by contrast, have been changing on shorter cycles. HTEC identifies this mismatch as a core ASIC disadvantage: rapidly evolving AI model architectures can outpace fixed-function designs. PwC’s 2026 semiconductor outlook echoes the concern, cautioning that architectural lock-in remains a key risk for hyperscalers making long-cycle custom silicon commitments.
For the custom silicon thesis to remain valid, three conditions need to hold:
- Workload stability: the inference workloads routed to ASICs must remain architecturally stable long enough for the chips to deliver return on their design investment.
- Sustained capex commitment: hyperscaler capital expenditure must stay elevated long enough to fund multi-year ASIC design and deployment cycles.
- Model architecture pacing: the rate of change in AI model architecture must not consistently outpace the ASIC design cycle, or the economic case for custom silicon erodes.
Why GPUs and ASICs are more complement than competition
The current hyperscaler model does not treat GPU and ASIC as a binary choice. Different task types are routed to different chip architectures based on workload characteristics. Frontier model R&D, where architectures change rapidly, continues to rely on GPUs. Stable, high-volume production inference is increasingly routed to ASICs. As Deloitte frames it, GPUs remain indispensable for frontier work even as ASICs handle production workloads.
This co-existence framing is the reason Nvidia’s continued dominance and Broadcom’s growth are not mutually exclusive outcomes. According to StartUs Insights, hyperscalers are deploying bespoke ASICs alongside Nvidia platforms, not replacing them.
The AI chip market is bigger, and more nuanced, than any single company
The AI chip market has two parallel and complementary growth stories unfolding simultaneously. One centres on general-purpose GPU dominance, where Nvidia remains the clear leader for frontier model training. The other centres on custom silicon specialisation, where Broadcom’s $4.1 billion quarter and 77% year-over-year growth demonstrate that the ASIC market is already operating at scale.
Investors and observers need both lenses to read the sector accurately. Treating every custom chip programme as a direct threat to Nvidia misses the complementary workload logic. Treating Broadcom’s revenue as a niche sideshow misses the structural demand underneath it.
For investors wanting to translate the structural analysis in this article into a portfolio framework, our dedicated guide to comparing Nvidia and Broadcom as AI investments examines forward P/E multiples, PEG ratios, debt profiles, and analyst consensus across both names, with explicit coverage of how the GPU and ASIC business models map to different risk tolerances.
The forward-looking signal to watch is whether hyperscaler capex remains elevated through 2026 and beyond. That spending, up approximately 54% in 2024 and increasingly directed toward agentic AI infrastructure, is the sustaining condition for both GPU and ASIC demand. If it holds, both growth stories continue. If it contracts, the higher-risk, longer-cycle ASIC investments would feel the pressure first.
This article is for informational purposes only and should not be considered financial advice. Investors should conduct their own research and consult with financial professionals before making investment decisions.
Past performance does not guarantee future results. Financial projections are subject to market conditions and various risk factors.