Nanoveu Runs Dual AI Voice Models on One Chip at Under Half a Milliwatt

EMASS fuses voice recognition and keyword detection on a single always-on chip
Nanoveu Limited (ASX: NVU, OTCQB: NNVUF) has reported that its EMASS unit demonstrated two AI voice functions, keyword detection and voice recognition, running simultaneously on its ECS-DoT edge AI co-processor at sub-milliwatt power, entirely on-device.
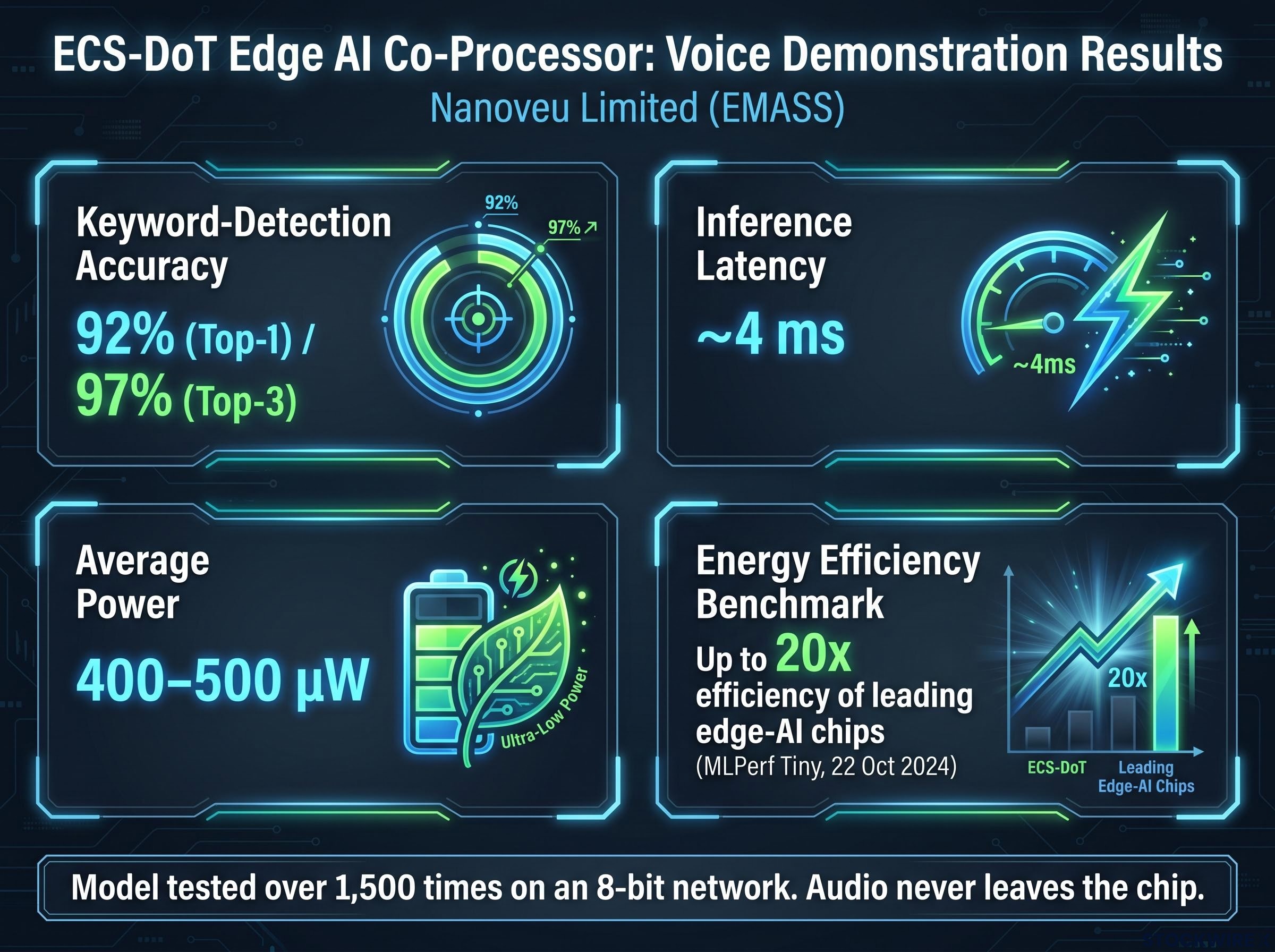
The demonstration marks the first time ECS-DoT has been shown running two AI functions at once, achieving 92% keyword-detection accuracy at roughly 4 ms latency while drawing 400–500 µW average power.
The significance for investors lies in what it proves: the platform can run multiple AI models concurrently, rather than a single, isolated voice block.
Headline figures from the demonstration include:
- Two AI functions fused on one always-on co-processor
- 92% top-1 / 97% top-3 keyword-detection accuracy
- ~4 ms inference latency, fast enough to feel instantaneous to the user
- 400–500 µW average power, on silicon independently benchmarked at up to 20x the energy efficiency of leading edge-AI chips (per MLPerf Tiny, 22 October 2024 announcement)
- Audio never leaves the chip
When big ASX news breaks, our subscribers know first
What the demonstration actually achieved
EMASS demonstrated two complementary voice capabilities on the ECS-DoT co-processor. The first is keyword detection, which recognises spoken commands and wake words in real time. The second is voice recognition, which confirms whether the person speaking is the enrolled, authorised user.
Together, the functions allow a device to respond to voice instantly while gating or personalising that response to the right person, all on-chip. Both capabilities run always-on while the host processor stays asleep. ECS-DoT performs continuous listening and wakes the device’s main processor only on a recognised command or a verified user, complementing rather than replacing the host CPU.
The keyword-detection model is a compact 8-bit network that was tested over 1,500 times to measure how reliably it identifies the correct spoken keyword. The voice-recognition model produces a per-user voice signature matched against an enrolled template.
Both functions were implemented on a standard ECS-DoT evaluation board using a standard PCM digital MEMS microphone, with no additional specialised hardware required.
CEO commentary on the platform implications
Mark Goranson, Nanoveu’s CEO of Semiconductor Technologies
“Today we are demonstrating two AI voice models, keyword detection and voice recognition, running together on ECS-DoT at sub-milliwatt average power, which is significant in its own right. But the bigger point is what it proves about the platform: ECS-DoT is multi-sensor and multimodal, so the same always-on engine is built to run image and other sensor models on these devices too. That provides optionality for device makers to add layered, low-power intelligence across voice, vision and beyond, while the main processor stays asleep.”
The power-latency-privacy trade-off explained
Delivering always-on voice on a compact, power-constrained device has traditionally been limited by a three-way trade-off between power, latency and privacy.
Keeping a microphone pipeline and a capable processor continuously active to listen for commands increases power consumption and thermal load. Duty-cycling those processors to save power, on the other hand, introduces latency and increases the risk of missed activations. An always-listening microphone that processes audio off the sensor also creates a persistent privacy surface.
Why does this matter to investors? Voice is becoming a primary control surface for computing devices, with the Voice AI Agents market projected to reach US$47.5 billion by 2034, according to Markets.us (April 2025). The ability to resolve the trade-off carries commercial weight.
ECS-DoT addresses this by performing the always-on sensing itself, at sub-milliwatt average power, and waking the host processor only when a recognised command or verified user calls for it. Because keyword detection and voice recognition run on-device, audio never needs to leave the chip.
| Property | Always-on mic + host CPU | Duty-cycled / wake-on-demand | ECS-DoT co-processor |
|---|---|---|---|
| Power | High & constant | Partial | <0.5 mW demonstrated |
| Latency / wake delay | None | Yes, but costly | ~4 ms at co-processor |
| Privacy | Audio off-sensor | Partial | Never leaves chip |
| Speaker verification | Host only | No | Yes, per-user signature on-device |
Beyond voice: a multimodal, multi-sensor platform
The strategic angle extends beyond this single voice demonstration. According to Nanoveu, the same engine running these voice models is built to run image, motion and other sensor models within a single ultra-low-power, always-on budget.
The company describes ECS-DoT as multi-sensor and multimodal by design. The capability demonstrated here forms the foundation for broader on-device, multimodal intelligence, rather than a single-function voice block. For device makers, this offers optionality to layer intelligence across voice, vision and beyond on one low-power co-processor.
ECS-DoT’s sub-milliwatt power envelope has already been validated in a different deployment context: live drone flight trials recorded up to 27.8% cruise efficiency gains, with the chip consuming less than 0.0002% of the drone’s total cruise energy across a 120-second flight.
The modalities the platform is designed to address include:
- Voice — instant, personalised, hands-free control through keyword detection and voice recognition (demonstrated)
- Vision — on-device image classification and presence or user recognition, with images never leaving the device
- Other sensors — motion and additional sensor streams fused with audio and vision
The next major ASX story will hit our subscribers first
Next steps toward commercial deployment
EMASS has outlined a roadmap to advance the always-on voice solution toward commercial deployment. The company notes this remains at the discussion and design-in stage.
-
Technical development — expanding the keyword vocabulary, hardening keyword detection and voice recognition performance across users and operating conditions, and progressing toward production-ready reference designs for computing devices.
-
Commercial engagement — active discussions with computing-device manufacturers, processors and platform integrators on deploying on-device voice modules.
-
Design-ins — pursuing design-in engagements to integrate ECS-DoT-based voice processors into next-generation tablets, PCs and always-on consumer and industrial endpoints.
The company has positioned ECS-DoT as an always-on intelligence layer for next-generation devices across high-value markets, including tablets, PCs, and consumer, professional and industrial endpoints.
For investors tracking how EMASS is funding the path from demonstration to production-ready silicon, our detailed coverage of the $7.5M capital raise outlines the dual-track strategy combining 16nm chip manufacturing through TSMC with the live field validation program underpinning commercial readiness.
Don’t Miss the Next ASX Tech Breakout
Big News Blast delivers FREE breaking ASX tech news and in-depth analysis directly to your inbox within minutes of release. Over 20,000 subscribers are already getting ahead of the market the moment announcements drop. Click the “Free Alerts” button at StockWire X to start receiving real-time alerts today.